Run this notebook online:![]()
Classification on Iris dataset with sklearn and DJL¶
In this notebook, you will try to use a pre-trained sklearn model to run on DJL for a general classification task. The model was trained with Iris flower dataset.
Background¶
Iris Dataset¶
The dataset contains a set of 150 records under five attributes - sepal length, sepal width, petal length, petal width and species.
| Iris setosa | Iris versicolor | Iris virginica |
|---|---|---|
 |
 |
 |
The chart above shows three different kinds of the Iris flowers.
We will use sepal length, sepal width, petal length, petal width as the feature and species as the label to train the model.
Sklearn Model¶
You can find more information here. You can use the sklearn built-in iris dataset to load the data. Then we defined a RandomForestClassifer to train the model. After that, we convert the model to onnx format for DJL to run inference. The following code is a sample classification setup using sklearn:
# Train a model.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
clr = RandomForestClassifier()
clr.fit(X_train, y_train)
Preparation¶
This tutorial requires the installation of Java Kernel. To install the Java Kernel, see the README.
These are dependencies we will use. To enhance the NDArray operation capability, we are importing ONNX Runtime and PyTorch Engine at the same time. Please find more information here.
// %mavenRepo snapshots https://central.sonatype.com/repository/maven-snapshots/
%maven ai.djl:api:0.28.0
%maven ai.djl.onnxruntime:onnxruntime-engine:0.28.0
%maven org.slf4j:slf4j-simple:1.7.36
import ai.djl.inference.*;
import ai.djl.modality.*;
import ai.djl.ndarray.*;
import ai.djl.ndarray.types.*;
import ai.djl.repository.zoo.*;
import ai.djl.translate.*;
import java.util.*;
Step 1 create a Translator¶
Inference in machine learning is the process of predicting the output for a given input based on a pre-defined model. DJL abstracts away the whole process for ease of use. It can load the model, perform inference on the input, and provide output. DJL also allows you to provide user-defined inputs. The workflow looks like the following:
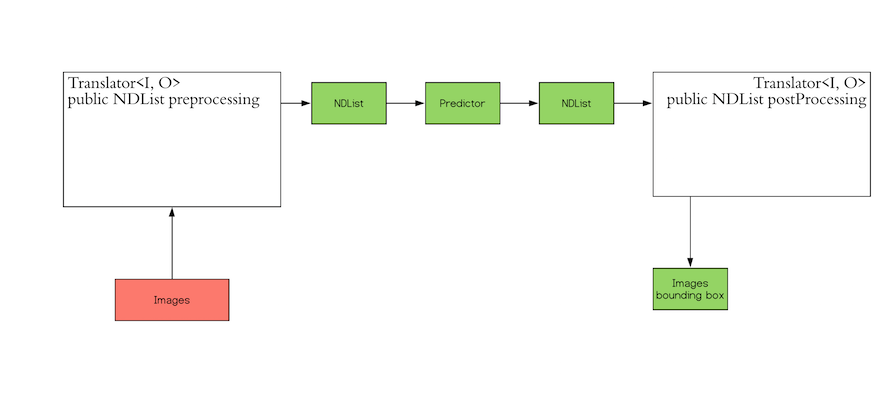
The Translator interface encompasses the two white blocks: Pre-processing and Post-processing. The pre-processing
component converts the user-defined input objects into an NDList, so that the Predictor in DJL can understand the
input and make its prediction. Similarly, the post-processing block receives an NDList as the output from the
Predictor. The post-processing block allows you to convert the output from the Predictor to the desired output
format.
In our use case, we use a class namely IrisFlower as our input class type. We will use Classifications as our output class type.
public static class IrisFlower {
public float sepalLength;
public float sepalWidth;
public float petalLength;
public float petalWidth;
public IrisFlower(float sepalLength, float sepalWidth, float petalLength, float petalWidth) {
this.sepalLength = sepalLength;
this.sepalWidth = sepalWidth;
this.petalLength = petalLength;
this.petalWidth = petalWidth;
}
}
Let's create a translator
public static class MyTranslator implements NoBatchifyTranslator<irisflower, classifications=""> {
private final List<string> synset;
public MyTranslator() {
// species name
synset = Arrays.asList("setosa", "versicolor", "virginica");
}
@Override
public NDList processInput(TranslatorContext ctx, IrisFlower input) {
float[] data = {input.sepalLength, input.sepalWidth, input.petalLength, input.petalWidth};
NDArray array = ctx.getNDManager().create(data, new Shape(1, 4));
return new NDList(array);
}
@Override
public Classifications processOutput(TranslatorContext ctx, NDList list) {
float[] data = list.get(1).toFloatArray();
List<double> probabilities = new ArrayList<>(data.length);
for (float f : data) {
probabilities.add((double) f);
}
return new Classifications(synset, probabilities);
}
}
Step 2 Prepare your model¶
We will load a pretrained sklearn model into DJL. We defined a ModelZoo concept to allow user load model from varity of locations, such as remote URL, local files or DJL pretrained model zoo. We need to define Criteria class to help the modelzoo locate the model and attach translator. In this example, we download a compressed ONNX model from S3.
String modelUrl = "https://mlrepo.djl.ai/model/tabular/softmax_regression/ai/djl/onnxruntime/iris_flowers/0.0.1/iris_flowers.zip";
Criteria<irisflower, classifications=""> criteria = Criteria.builder()
.setTypes(IrisFlower.class, Classifications.class)
.optModelUrls(modelUrl)
.optTranslator(new MyTranslator())
.optEngine("OnnxRuntime") // use OnnxRuntime engine by default
.build();
ZooModel<irisflower, classifications=""> model = criteria.loadModel();
Step 3 Run inference¶
User will just need to create a Predictor from model to run the inference.
Predictor<irisflower, classifications=""> predictor = model.newPredictor();
IrisFlower info = new IrisFlower(1.0f, 2.0f, 3.0f, 4.0f);
predictor.predict(info);